Code Quality Rank
You need no technical qualification to understand what happens under the hood of your project. Based on analyzing 2.5 bln. lines of code and 172k repositories we found it possible to condense a code quality summary to the one letter rank.
Rating

Main Idea
Our product is based on the idea of simplicity. Any person who doesn’t even have a special technical background, will be able to understand immediately what is happening with the codebase by just looking at the results of our analysis: is it getting better, or, perhaps, it’s only getting worse; see who and when introduced low-quality code or vice versa—has cleaned the Augean stables.
As a result of negotiations, such a global high-level idea has transformed into the idea of ratings.
How Does Rating Work?
As we have already mentioned, the rating is a generalized assessment. So, it generalizes something and consists of multiple parts. Yes, it is true.
Obtain stats from SonarQube;
Feed the resulting statistics to our algorithm; ???
PROFIT!!! The rating is calculated!
Several Technical Details
So, as we have already found out, each commit and repository differ by the number of code lines used by technology and language, as well as the number and type of violations. Our goal is to make sure that the resulting estimates are independent of these parameters, in other words, so that you can:
- Compare the code written in one language but in different volumes;
- Compare the code written in different languages;
- Compare developers;
- Compare repositories.
For this purpose, we have used the following approach, which optimally meets our goals.
First of all, without a model and an approach, we can nevertheless easily compare repositories with the same or almost the same number of lines of code using the same programming language. And as the main criterion for comparison, we will have the number of violations of a certain type (Minor, Major, Critical, Blocker).
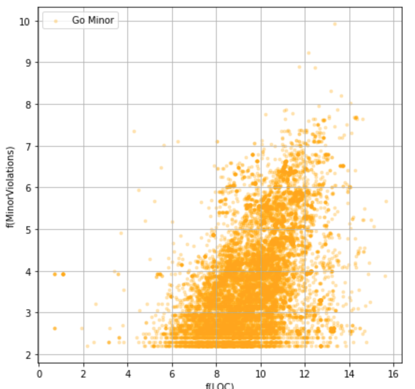
Fig. 1 - Dependence of Minor Violations number on LOC Repository Size for Golang
Having downloaded hundreds of thousands of repositories from GitHub, we conducted an exploratory analysis of how often violations of a certain type are found in repositories of a certain size. In simpler words—how many violations will be in small repositories, and how many in large ones. And, as expected, the larger the repository, the more violations we could find in it.Let's finally look at the charts and discuss what we’ve got. The following graphs showhow the number of Minor Violations (vertical) differs for Java and Golang depending onthe repository size (horizontal).
Based on the charts, it is clear that with small number of code lines in the repository, the number of violations is still higher for Java, because, firstly, the graph of the point for Java is shifted to the left (towards fewer lines of code), and, secondly, it has greater height (i.e. more violations).This data can also be viewed from another side. Let's see how violations are distributed in repositories with the same (well, almost the same) number of code lines.
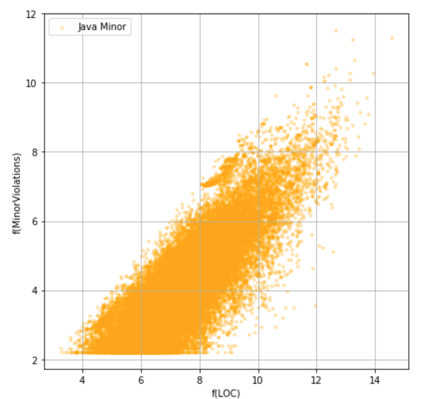
Fig. 2 - Dependence of Minor Violations number on LOC Repository Size for Java
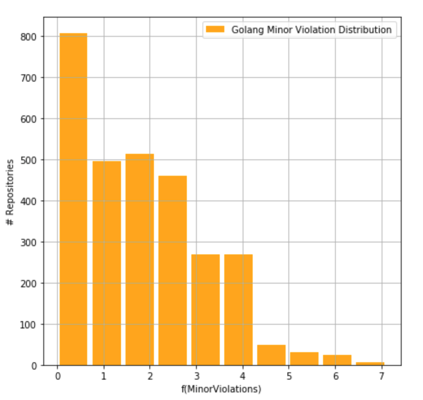
Fig. 3 - Number of Golang repositories having a certain number of violations
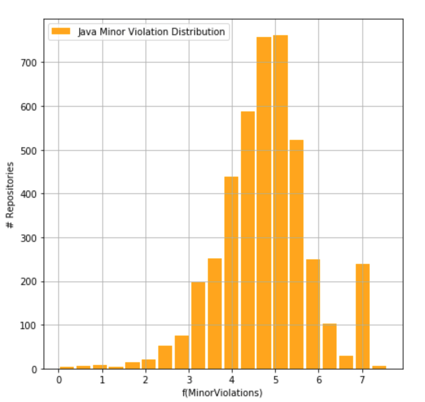
Fig. 4 - Number of Golang repositories having a certain number of violations
Figures 3 and 4 show that Golang repositories are characterized by the fact that a lot of repositories have an insignificant number of violations: the graph “sticks” to the left edge. A different picture is intrinsical for Java repositories: there is a “wave,” the top of which indicates the most usual number of errors in the repository of a given size. And this most characteristic value is much higher in Java than in Golang.
So, for the second time, we are convinced that writing simple code in simpler languages is easier!
And SonarQube confirms this. This is the proof that you have been waiting for.
How To Compare Repositories With Each Other?
Obviously, the repository containing no violations at all will always get the best rating. But what if, for example, there are ten violations in a repository? Is it a lot or not? It all depends on the number of code lines in your repository. If there are only ten of them, then this is not very comforting news for you! But if there are hundreds of thousands of lines of code, then this is already a fairly clean code. Is it possible to say that in this case, these two repositories are comparable in the code quality?
Our algorithm answers this question by setting an appropriate rating for the code quality depending on the number of lines, and number and types of violations encountered in this repository.
In other words, we compare the number of code lines in the newly analyzed repository against the already analyzed ones for a given language. Then, we find repositories similar in volume and look at the number of violations in the analyzed repository in comparison to those we already have analyzed. If it’s low, we mark the code as good, if there are a lot of violations, the mark is worse.
How to Compare Two Ratings For Different Languages?
It’s very easy! You simply compare the ratings with each other, without thinking about what language your repository is in, nor about how many lines of code are there in it! Our approach frees you from these worries! Repositories become comparable regardless of language and number of code lines!
Thus, our algorithm fully meets the goals.
Why Didn’t You Choose Another Approach?
We have experimented with different approaches.
The simplest approach was based on a simple comparison of violation density. But the key drawback of this approach was that it made it impossible to compare repositories using different programming languages. Such an approach, with all its simplicity, was limiting the possibility of its use by the framework of one language. Estimates became incomparable.
We have also experimented with well-known machine learning approaches—classification and clustering. But, as the practice has shown, and you saw it from the graphs above, there are no clusters in the distribution of the number of errors in the repositories.
With the classification, the problem was even more interesting. Since classification requires labeled data (there should have been indications of whether the code in the repository is good or bad), the problem turned out to be an Ouroboros. We need quality classes of program code, but to get them, we need to build a classification model. And to build a classification model, you need quality classes of program code.
Only the good old statistical approach was left, which we have used. Our approach is based on the construction of a multidimensional probability density function for errors in the source code, the level lines of which are our ratings. And this approach is working! Moreover, this approach fully satisfies our requirements for the rating system.
Pros And Cons of Our Rating System
- Simplicity and clarity even for a software development newcomer;
- The ability to compare developers writing in the same language;
- The ability to compare developers using different languages;
- The ability to compare repositories by code quality;
- The honesty of the Rating System.
What Does Honesty Mean?
Here I would like to talk about one case.
We’ve built rating models for different languages and launched them on in-house production servers. As we work and scan the repositories and commits inside the company, we have accumulated some data displayed on our dashboard.
And then, something unexpected happened! It turned out that the ratings of Java, JavaScript, and PHP developers were on average worse than those of Golang developers! And, of course, the blame was on the DS department, which was said to set up these rating models, strongly discriminating individual languages and technologies!
The DS department just pointed out that we had just really great Golang developers, without going into details. Such excuses satisfied the unsatisfied group only for a short time. And finally, when the situation was already quite tense and the people began to demand answers, the DS department started an internal investigation, the result of which is this article. The purpose of this article is to add transparency and clarify the understanding of the principles of the constructed rating system. After all, no one likes when their work is evaluated by some mysterious model that works, as it seems, like a black box.



